Taming popularity bias in recommender systems with logit adjustment
My recommender kept handing everyone the same blockbusters. Here’s how I got it to surface the niche films that actually fit each user’s taste.
Picture a die-hard WW2 movie buff. Their watchlist is Saving Private Ryan, Enemy at the Gates, Stalingrad, The Great Escape. You ask the recommender: what next?
Here’s what my two-tower model returned — the same user, the same architecture, the same code path — for two versions of the model: one trained with a popularity-debiasing correction, one without.
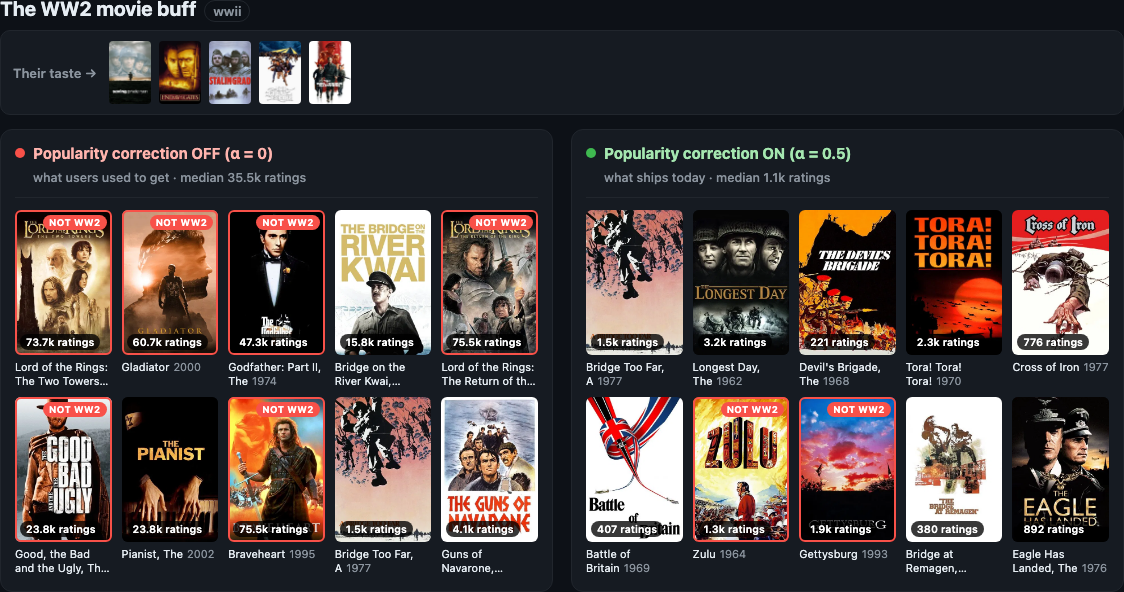
Look at the left wall (the “before”). For a WW2 fan, the model serves up Braveheart (medieval Scotland), Gladiator (ancient Rome), The Lord of the Rings — twice (Middle-earth), and The Godfather Part II (the Mob). Six of the ten aren’t even war movies. What they are is massively popular — Braveheart alone has 75,514 ratings. The model didn’t recommend war films.
Now the right wall (the “after”). The Devil’s Brigade. Cross of Iron. Tora! Tora! Tora! Battle of Britain. Actual war films — most with a few hundred ratings, the kind of catalog depth a real enthusiast actually wants. The median recommendation went from 35,547 ratings to 1,083 — roughly 33× less mainstream — and it got more on-genre, not less.
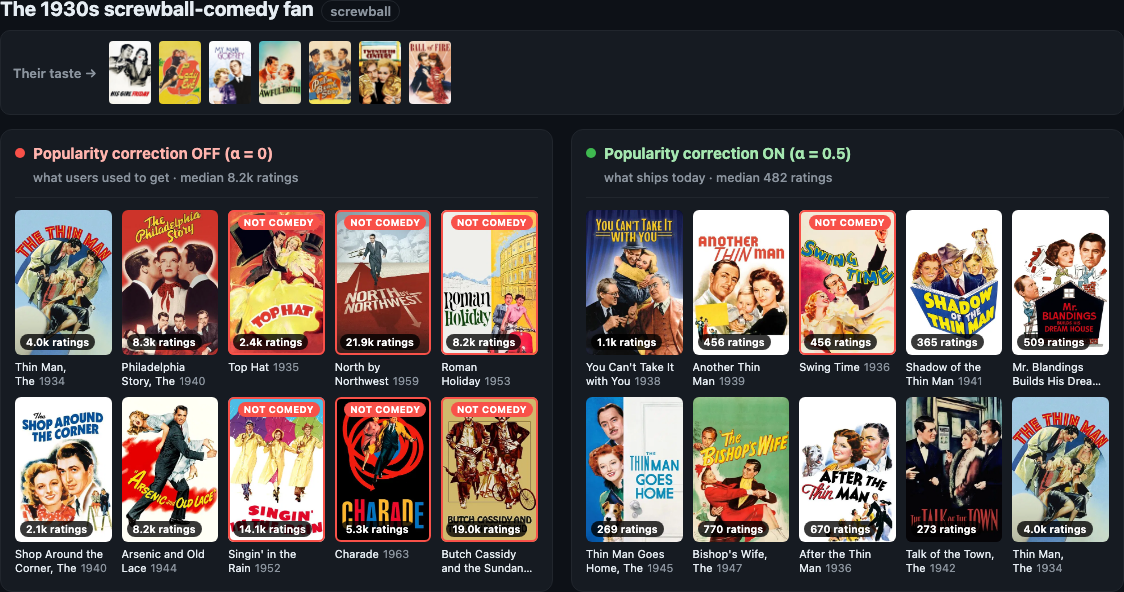
This isn’t a WW2 quirk — the same before/after holds for every taste I tried. See six more fans — high-fantasy, crime, courtroom, vintage sci-fi, giallo horror, and screwball comedy — in the Appendix (the courtroom fan’s “before” wall is practically the literal IMDb Top 10).
What’s actually going wrong here
This is popularity bias, and it’s a feedback loop, not a bug:
- Popular movies get shown more, so they collect more clicks.
- You train on those clicks, so the model learns “popular = good.”
- The model shows popular movies even more. Go to step 1.
Left alone, your “personalized” recommender slowly collapses into a Most Popular shelf — it hands everyone the same blockbusters and quietly buries the entire long tail of the catalog.
The fix
This comes straight from a 2020 paper, “Long-Tail Learning via Logit Adjustment” (Menon et al.). The idea is almost suspiciously simple:
During training, add a bonus to every movie’s score equal to how popular it is — including the negatives.
# during training only: add each movie's log-popularity to its score
scores = user · movie_embeddings + α · log(1 + rating_count)The correction lives entirely in training — you just retrain a new model. Serving doesn’t change, which makes it very easy to A/B test online.
The strength is one knob, α. At α=0 you get the blockbuster wall. Crank it too high and you over-correct into pure obscurity. I tuned it to α=0.5 — enough to fix the drift, not so much that Saving Private Ryan never shows up.
How it works
Why does adding a popularity bonus reduce popularity bias? The model trains as a full softmax: each example scores the true next movie against every movie in the catalog, and the bonus α · log(popularity) is added to all of them. So in every training step, popular movies sit among the negatives with a head start. The model can only drive the loss down by scoring the true movie high enough to beat those boosted popular negatives — it’s forced to clear a higher bar specifically against popular titles. Repeat over millions of examples and the model learns scores that encode relevance net of popularity: a movie ranks high only when you’d like it more than its raw popularity already predicts. At serving you drop the bonus and rank on those scores — so a niche film you’re a perfect match for can finally outrank a blockbuster everyone half-watches.
For the math-inclined: the objective’s optimum drives each raw score toward
log P(movie | you) − α · log(popularity)— contextual relevance with the base rate divided back out. The bonus exists only in training; at serving you rank on the raw score, which has already absorbed that popularity discount. It’s the Fisher-consistent result from the paper, not a heuristic.
Why this beats the usual post-ranking hacks
Most teams fight popularity bias after the model — demotion multipliers, per-page blockbuster caps, a bolted-on diversity re-ranker — heuristics nobody fully trusts that rot as the catalog shifts and add a stage to the serving path. Logit adjustment is the opposite: one line in the loss, mathematically grounded (the Fisher-consistent term from the box above, not an eyeballed constant), and trivial to maintain — the whole behavior is one hyperparameter you re-tune in the next retrain if your team finds the debiasing too aggressive.
It’s not even two-tower-specific: the correction lives in the softmax, so it drops into any model trained with cross-entropy over candidate items — ranking models included.
Does it hold up beyond a couple of cherry-picked fans?
I ran both models over 60,000 held-out recommendation contexts from 3,000 real users and measured the popularity of what they actually served:
| Before (α=0) | After (α=0.5) | ||
|---|---|---|---|
| Median recommendation popularity | 26,830 ratings | 13,200 | ↓ 51% |
| Catalog coverage (distinct films ever shown) | 4,485 (48%) | 7,899 (84%) | +3,414 movies |
| Exposure inequality (Gini) | 0.907 | 0.776 | more equal |
| Long-tail share of recommendations | 0.2% | 4.3% | ~20× |
The median recommendation got half as mainstream, and the model went from surfacing 48% of the catalog to 84% — 3,400+ movies that previously had zero chance of being recommended to anyone.
No free lunch: the catch
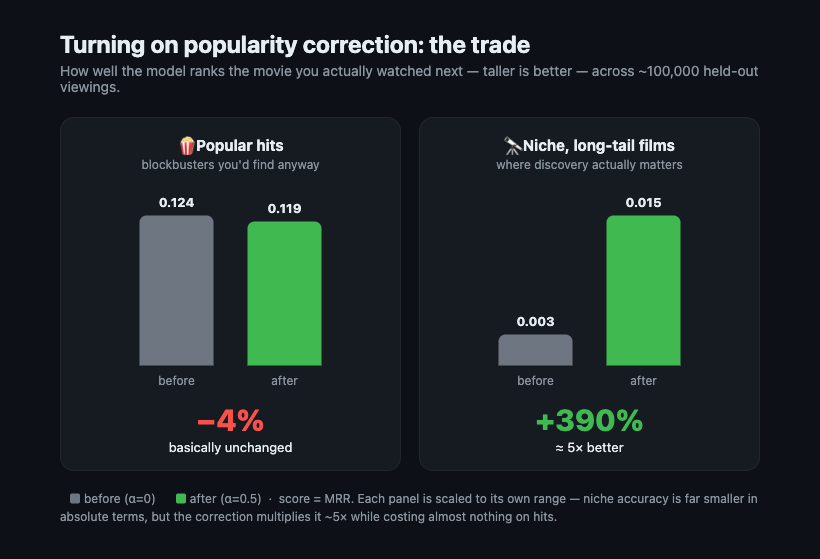
Demoting popular titles isn’t free, and any honest writeup has to show the bill. Held-out viewings skew popular — that’s literally what popularity bias is — so when you down-weight popular movies, some of those held-out favorites get ranked a notch lower. Across the same ~100,000 held-out viewings, scored by both models:
| Overall ranking accuracy | α=0 | α=0.5 | |
|---|---|---|---|
| MRR | 0.120 | 0.115 | −4.3% |
| Recall@10 | 0.230 | 0.220 | −4.4% |
| NDCG@10 | 0.135 | 0.129 | −4.1% |
About 4% off the top line. Real — but look at where the bill is paid:
| MRR, split by how popular the held-out movie was | α=0 | α=0.5 | |
|---|---|---|---|
| Popular head (>1,000 ratings) | 0.124 | 0.119 | −4.7% |
| Long tail (≤1,000 ratings) | 0.0031 | 0.0152 | +390% |
The entire cost lands on the popular head — the blockbusters the model already nails and that barely need a recommender to be found. Meanwhile the long tail gets 5–12× more accurate (tail Recall@10 climbs from 0.2% to 3%): still hard in absolute terms, but no longer hopeless — and that’s exactly the region where a recommender earns its keep.
So the honest trade is: give up ~4% accuracy on movies everyone already knows, to make the other 84% of the catalog findable at all.
But doesn’t that hurt people who like the popular stuff?
That −4.7% on the popular head is the objection an interviewer always pushes on: if the model spends its budget discounting popularity, what happens to the user whose taste genuinely is mainstream — or who loves a niche but watches its recent, popular entries? Does α=0.5 exile them to the long tail too?
No. I ran the same two twins on exactly those users.
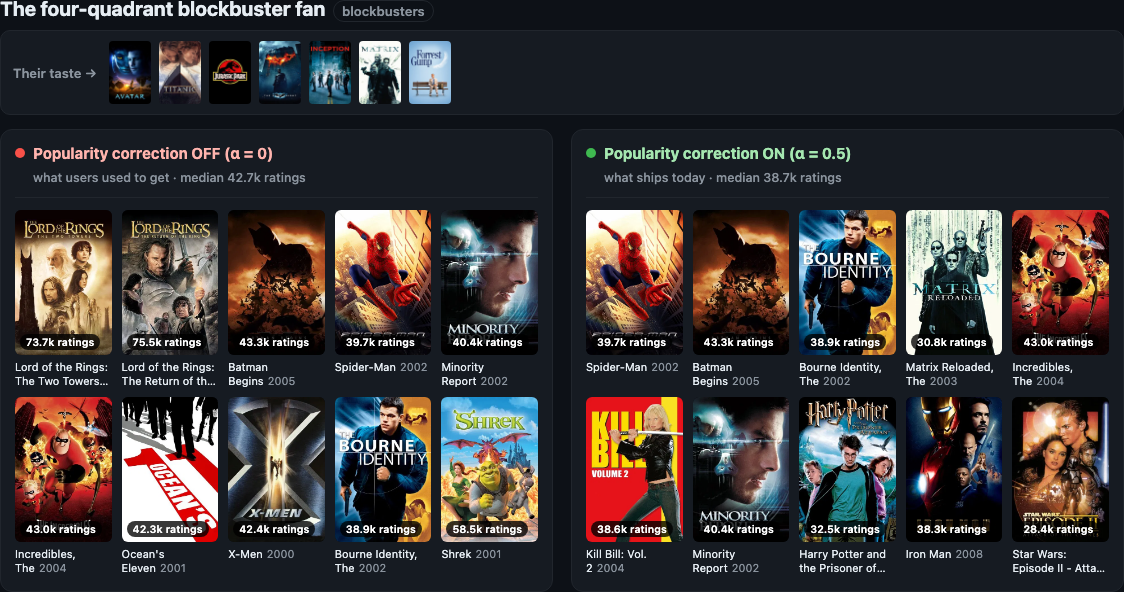
A pure-blockbuster fan — liked nothing but the four-quadrant canon (Avatar, Titanic, Jurassic Park, The Dark Knight, Inception, The Matrix…), every seed north of 27k ratings. The α=0.5 wall comes back Spider-Man, Batman Begins, Iron Man, The Incredibles, Minority Report, Harry Potter — still blockbusters, all of them. The median recommendation moves 42,700 → 38,700 ratings: a rounding error. When mainstream really is your taste, the correction leaves you there.
A modern sci-fi fan — Inception, Interstellar, Ex Machina, Arrival, District 9, Moon — a genre devotee who watches 2010s films, not 1950s ones. This is the case people expect α to break: surely demoting popularity dumps them into Forbidden Planet and 2001? It doesn’t. α=0.5 cuts the median recommendation 2.3× (15,100 → 6,500 ratings) — real work — yet every pick stays modern, on-genre sci-fi: Oblivion, Prometheus, Sunshine, Primer, Coherence, Predestination, all 2004–2014. The discount surfaced modern catalog depth, not vintage classics.
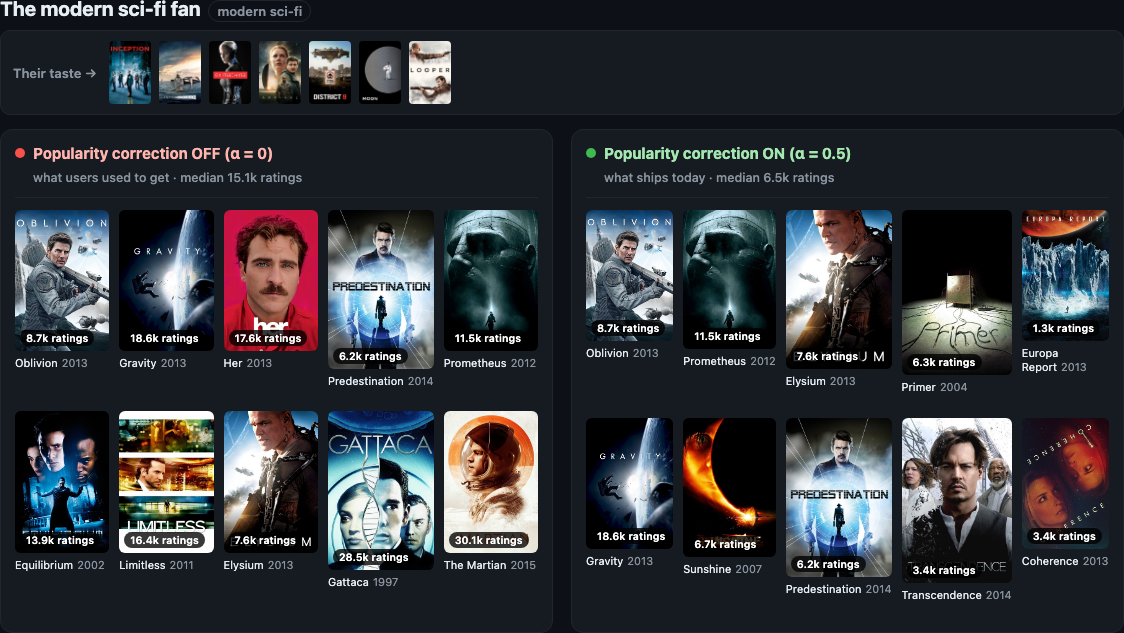
That’s the payoff of doing this in the loss rather than with a blunt post-filter: it discounts popularity relative to how well a title matches you, so the films you genuinely match still score high. α=0.5 stops the model pushing blockbusters on people who don’t want them; it doesn’t take them from the people who do. (Same result on every profile I checked — modern superhero, Pixar-era animation, action, crime-thriller, post-2000 horror: each stayed in recent, on-genre films.)
The takeaway
Most “fix the recommender” projects mean a bigger model, more features, more compute. This one was a single term in a loss function, grounded in a clean piece of theory, that:
- halved the popularity of recommendations,
- nearly doubled catalog coverage,
- made the long tail 5–12× more findable,
- cost ~4% head-accuracy and zero added latency.
Appendix: More examples
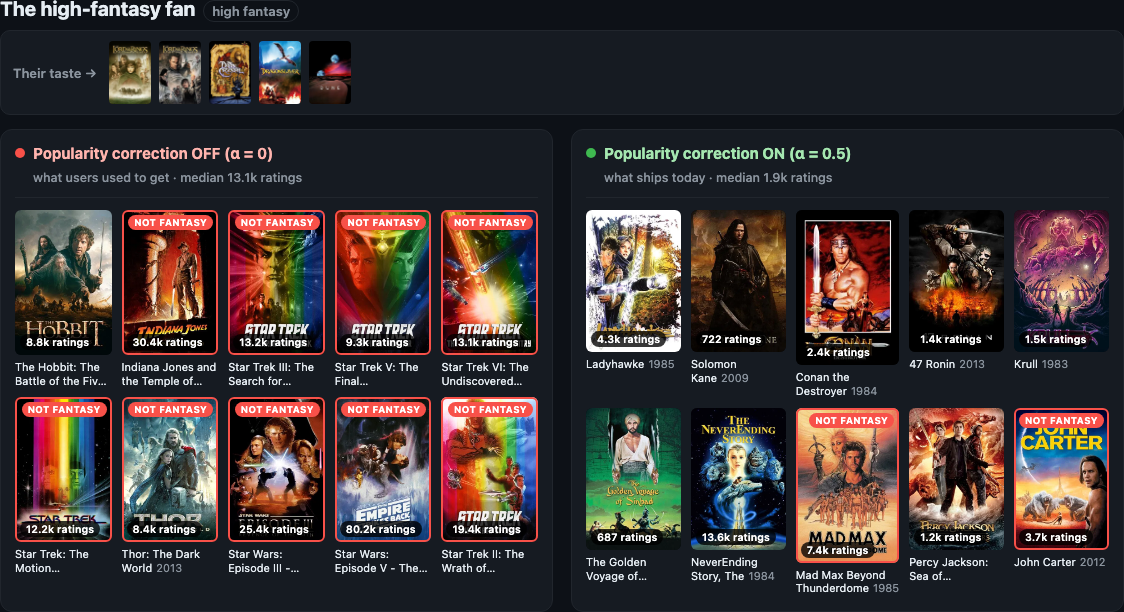
High-fantasy fan
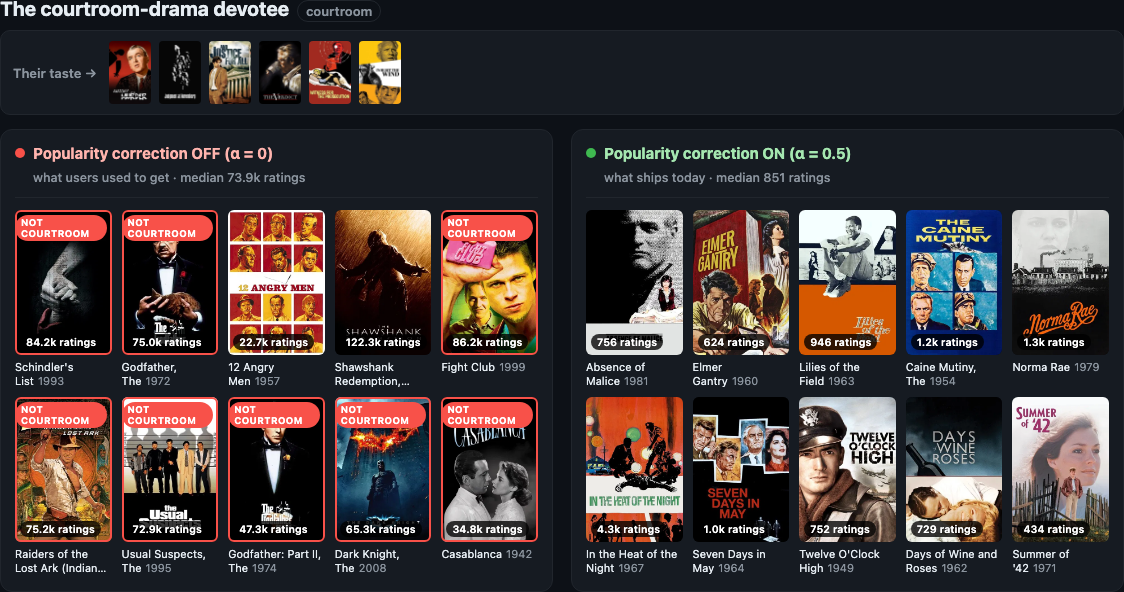
Courtroom-drama fan
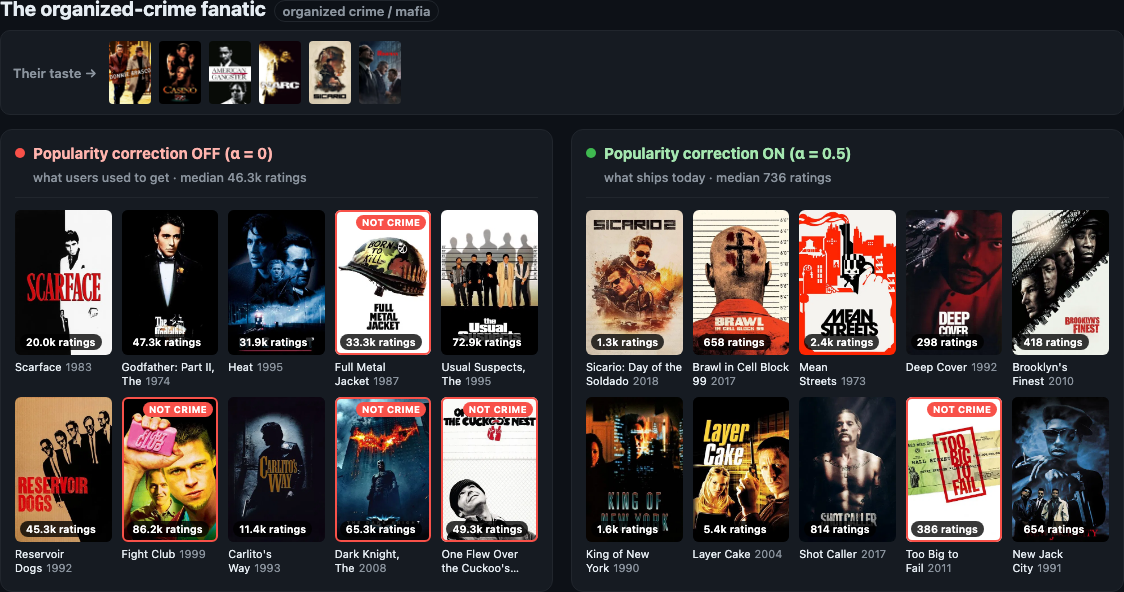
Organized-crime fan
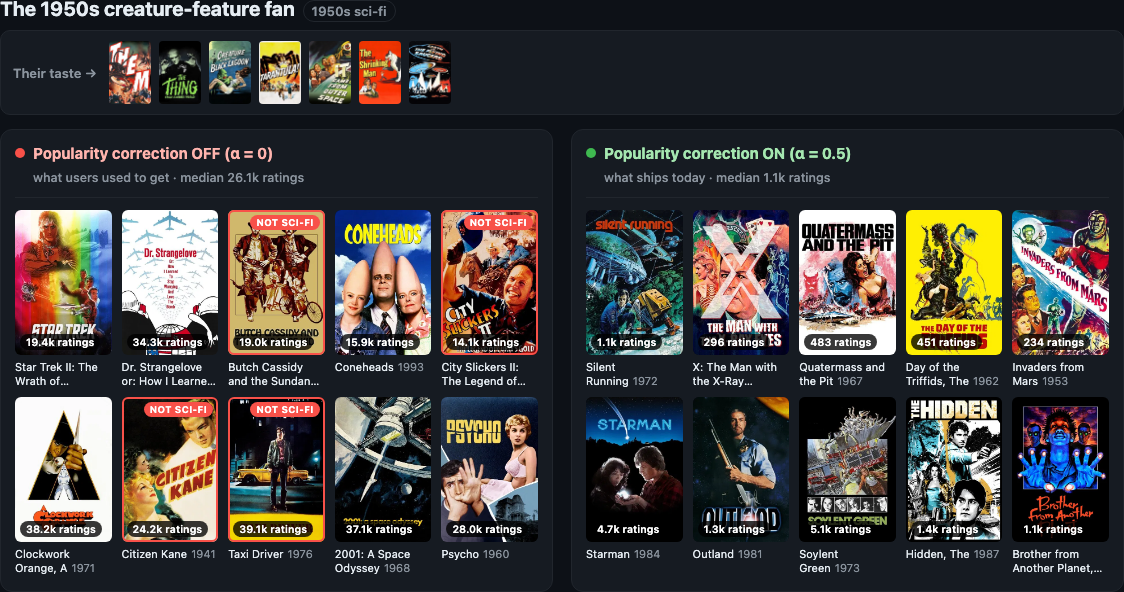
1950s creature-feature fan
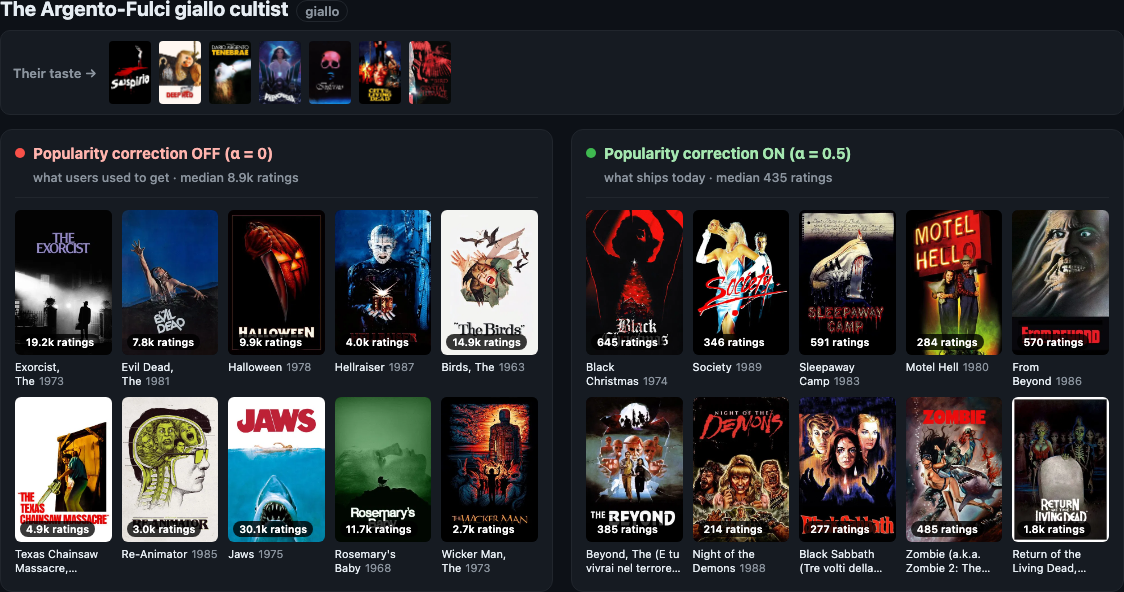
Argento-Fulci giallo cultist
1930s screwball-comedy fan